Fuentes tipográficas y escritura digital en lenguas originarias
Utilizar fuentes tipográficas adecuadas es de importancia crítica para las lenguas originarias de México y del mundo. Muchas de estas lenguas emplean glifos (letras) que no son comunes en lenguas hegemónicas como el español, y las fuentes más populares suelen ofrecer un repertorio limitado, restringido a los caracteres más frecuentes en esas lenguas.
Algunas de las lenguas más habladas de México, como la mayoría de las variantes del Maya, el Náhuatl o el Totonaco, no requieren caracteres especialmente inusuales debido a sus características ortográficas. Pero otras lenguas nacionales —particularmente las lenguas tonales como el Chinanteco o Mixteco— incluyen una rica variedad de símbolos para reflejar su riqueza tonal y fonológica. En estos casos, el problema se vuelve crítico: estas suelen ser también las lenguas más amenazadas, y que sus textos no reflejen adecuadamente los caracteres correctos genera inconsistencias que fragmentan progresivamente la escritura y deterioran esa riqueza. Esto constituye en sí mismo una forma de rezago y violencia lingüística.
El problema en la práctica: la I barrada
Un ejemplo concreto y frecuente: en lenguas tonales como el Chinanteco o el Mixe existe un carácter llamado "I barrada" — ɨ (U+0268) — que generalmente representa una vocal cerrada central no redondeada. Dado que es un carácter poco común en los alfabetos latinos estándar, con frecuencia se le sustituye por el signo de más (+). Pero esta es una solución inconsistente: otras editoriales o instituciones pueden optar simplemente por escribir i, i- o -i, lo que dificulta la comprensión y fragmenta la escritura de la lengua.
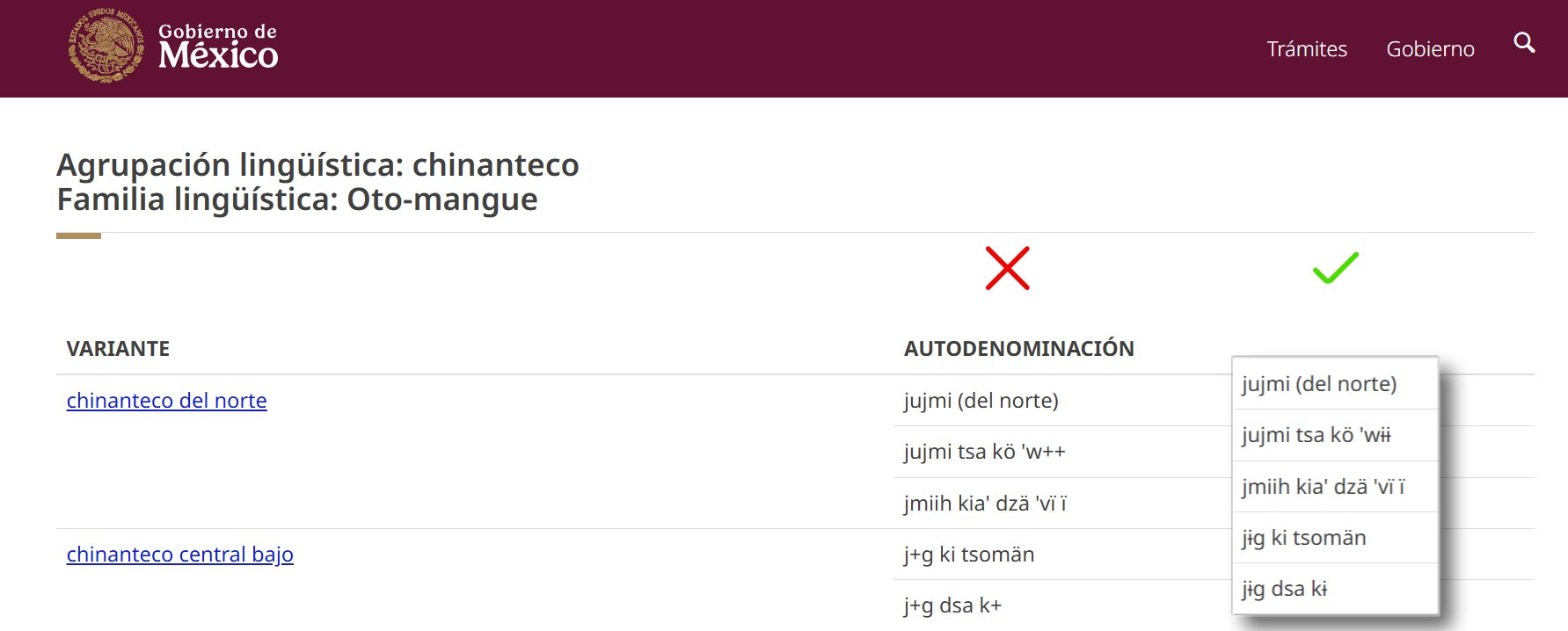
Uso subóptimo del signo + en sustitución del carácter correcto ɨ con una fuente que lo soporta adecuadamente.
El problema va más allá de la apariencia. El signo + tiene un comportamiento digital distinto al de un carácter que representa una letra: puede generar errores al imprimir, al procesar texto, al realizar búsquedas o al usar herramientas tecnológicas. En medios digitales, el documento que debería ser un recurso lingüístico confiable se convierte en un texto técnicamente defectuoso.
Lo mismo ocurre con las marcas tonales: sustituirlas por texto subrayado es una práctica igualmente problemática. El subrayado es un formato de estilo, no un carácter único. Los softwares lo tratarán como tal, y es muy probable que este formato se pierda al imprimir, copiar, cambiar de aplicación o mostrar el texto en medios digitales. Al seleccionar y copiar el texto, el estilo puede no preservarse y la marca tonal desaparece, haciendo que la palabra pierda su significado.
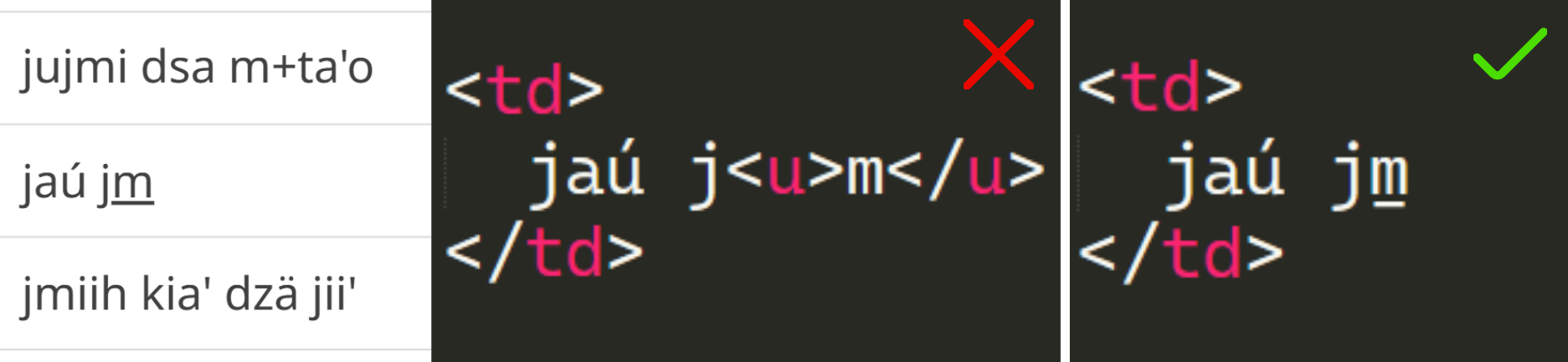
Uso subóptimo de marca de subrayado (estilo) vs uso de caracter con macron inferior fara indicar tono
Estos caracteres no son decoraciones opcionales ni detalles menores. En muchos casos son necesarios para la comprensión del texto, y su omisión o sustitución produce degradación real en la calidad y la riqueza de la lengua.
Si bien existen ortografías modernizadas que en ocasiones simplifican este problema, en Tachiwin pensamos que la solución no es abandonar estas grafías, sino encontrar los mecanismos digitales para escribirlas de manera correcta y práctica. Entendemos que a nivel personal e informal los hablantes puedan verse obligados a usar sustituciones; sin embargo, a nivel institucional estas sustituciones no deberían permitirse intencionalmente con el objetivo de facilitar procesos.
Recomendaciones para programadores: UTF-8 como estándar
Si desarrollas software, sitios web, bases de datos o cualquier herramienta que maneje texto, la recomendación es clara: usa UTF-8 en absolutamente todo.
UTF-8 es el estándar de codificación de caracteres más universal que existe. Fue diseñado para representar prácticamente cualquier sistema de escritura del mundo —incluyendo todos los caracteres de las lenguas originarias de México— sin necesidad de codificaciones especiales o tablas alternativas. En contraste, estándares más antiguos como ASCII o ISO-8859-1 sólo cubren un subconjunto muy limitado de caracteres latinos, dejando fuera a la inmensa mayoría de los glifos que estas lenguas requieren.
Buenas prácticas concretas:
- Declara siempre
charset=UTF-8en tus documentos HTML. - Configura tus bases de datos con collation
utf8mb4(no soloutf8, que en MySQL es incompleto). - Guarda todos tus archivos de texto, CSV y código fuente en UTF-8.
- Evita convertir o exportar a ASCII o Latin-1, ya que esto destruirá los caracteres especiales.
Cómo escribir caracteres especiales
Si necesitas escribir un carácter que no aparece en tu teclado, estas son las formas más prácticas:
En Windows:
Abre el Mapa de caracteres (busca "Mapa de caracteres" en el menú inicio), selecciona la fuente adecuada, localiza el carácter y cópialo. También puedes usar la combinación Alt + código numérico en el teclado numérico para algunos caracteres, aunque este método es limitado y poco confiable para caracteres fuera del rango ASCII extendido.
En macOS:
Abre el Visualizador de caracteres con Ctrl + Cmd + Espacio. Puedes buscar el carácter por nombre (por ejemplo, "latin small letter i with stroke") y hacer doble clic para insertarlo.
Método universal: Copiar y pegar desde una fuente confiable siempre funciona. Puedes usar sitios como Unicode Character Table para encontrar y copiar cualquier carácter por su nombre o código.
Caracteres frecuentes en lenguas originarias de México no soportados por fuentes comunes
Revisamos más de 2,200 fuentes y encontramos que menos del 2% soporta completamente el conjunto de caracteres necesario para las lenguas originarias de México. 🔎
Cuando una fuente no soporta un carácter, en su lugar se muestra un cuadrado vacío □ o un signo de interrogación, lo que indica que el glifo no está disponible en esa fuente.
Estos son los caracteres que con mayor frecuencia no son soportados por fuentes convencionales. Al elegir una fuente para documentos en lenguas originarias, conviene verificar que los muestre correctamente:
| Carácter | Código Unicode | Nombre |
|---|---|---|
| ƚ | U+019A | Latin Small Letter L with Bar |
| ꞌ | U+A78C | Latin Small Letter Saltillo |
| ʌ | U+028C | Latin Small Letter Turned V |
| ʉ | U+0289 | Latin Small Letter U Bar |
| ɛ | U+025B | Latin Small Letter Open E |
| ɨ | U+0268 | Latin Small Letter I with Stroke |
| ⁿ | U+207F | Superscript Latin Small Letter N |
| ‑ | U+2011 | Non-Breaking Hyphen |
| ˊ | U+02CA | Modifier Letter Acute Accent |
| ˋ | U+02CB | Modifier Letter Grave Accent |
| ḻ | U+1E3B | Latin Small Letter L with Line Below |
| ṉ | U+1E49 | Latin Small Letter N with Line Below |
| ǔ | U+01D4 | Latin Small Letter U with Caron |
| ǎ | U+01CE | Latin Small Letter A with Caron |
| ə | U+0259 | Latin Small Letter Schwa |
| ʼ | U+02BC | Modifier Letter Apostrophe |
| ˉ | U+02C9 | Modifier Letter Macron |
| ǿ | U+01FF | Latin Small Letter O with Stroke and Acute |
| ŋ | U+014B | Latin Small Letter Eng |
| į | U+012F | Latin Small Letter I with Ogonek |
| ō | U+014D | Latin Small Letter O with Macron |
| ā | U+0101 | Latin Small Letter A with Macron |
| ī | U+012B | Latin Small Letter I with Macron |
| ē | U+0113 | Latin Small Letter E with Macron |
| ū | U+016B | Latin Small Letter U with Macron |
| ž | U+017E | Latin Small Letter Z with Caron |
| š | U+0161 | Latin Small Letter S with Caron |
Además de los caracteres individuales, conviene verificar que la fuente soporte los siguientes diacríticos combinantes (que se aplican sobre otras letras):
| Carácter | Código Unicode | Nombre |
|---|---|---|
| ◌̱ | U+0331 | Combining Macron Below |
| ◌̨ | U+0328 | Combining Ogonek |
| ◌̄ | U+0304 | Combining Macron |
| ◌̈ | U+0308 | Combining Diaeresis |
| ◌̃ | U+0303 | Combining Tilde |
| ◌́ | U+0301 | Combining Acute Accent |
Fuentes recomendadas por Tachiwin ✅
En Tachiwin nos dedicamos a probar fuentes de código abierto para identificar cuáles tienen cobertura prácticamente total de los glifos de las lenguas originarias de México. Las siguientes fuentes han superado esta revisión y su buen funcionamiento con textos en lenguas originarias está prácticamente garantizado. Las recomendamos especialmente para documentos que busquen universalidad, como traducciones y plantillas gubernamentales.
Esta lista está en constante revisión y actualización:
| Fuente | Proveedor | Licencia |
|---|---|---|
| Andika | Google Fonts | OFL |
| Arimo | Google Fonts | OFL |
| Charis SIL | Google Fonts | OFL |
| Gentium Book Plus | Google Fonts | OFL |
| Gentium Plus | Google Fonts | OFL |
| Libertinus Serif | Google Fonts / GitHub | OFL |
| Merriweather | Google Fonts | OFL |
| Noto Sans | Google Fonts | OFL |
| Noto Sans Display | Google Fonts | OFL |
| Noto Sans Mono | Google Fonts | OFL |
| Noto Serif | Google Fonts | OFL |
| Noto Serif Display | Google Fonts | OFL |
Asimismo, cuando se desarrolle una fuente totalmente nueva —como en el caso del gobierno federal— sugerimos solicitar la inclusión explícita de los caracteres listados arriba para facilitar su uso institucional con lenguas originarias.
Tachiwin OCR 1.5 y el reconocimiento de caracteres especiales
Parte de este problema también ocurre a la inversa: cuando se digitalizan documentos históricos o impresos en lenguas originarias, los modelos de OCR convencionales no reconocen estos caracteres especiales y los omiten o sustituyen por aproximaciones incorrectas.
Por eso en Tachiwin desarrollamos Tachiwin OCR 1.5, un modelo especializado en la digitalización de textos en lenguas originarias de México. A diferencia de los modelos genéricos, fue entrenado específicamente para reconocer los caracteres latinos no estándar y los glifos propios de estas lenguas, reduciendo significativamente los errores en la transcripción de documentos históricos y contemporáneos. Puedes probarlo en línea o acceder al modelo open source.
Lo que estamos haciendo al respecto 🛠️
Tachiwin trabaja actualmente en una app de teclado para Android con teclados especializados para cada lengua originaria de México, para que los hablantes de cada variante puedan escribir su lengua sin sustituciones y con facilidad. Mantente pendiente de nuestras actualizaciones.
Apoya nuestra causa para que sigamos trabajando en favor de la inclusión digital de las lenguas originarias de México a través de un donativo mensual o por única ocasión. 💙